




Als ich mit dem PIVOT-Konstrukt arbeitete und performante Ergebnisse haben wollte, muss ich erst verstehen, wie es intern arbeitet. Das beschrieb ich im Artikel "SQL-Server-2005: schnelles Pivot?". Diese Serien soll meine Erfahrungen weitergeben und bei Verstehen der Zusammenhänge helfen. Mit ein paar Kniffen kann man dann die Ausführung erheblich beschleunigen. Das kommt im nächsten Artikel. Der Quellcode zu diesem Artikel steht übrigens hier.
- Artikel 1: Wie wird Pivot abgearbeitet?
- Artikel 2: Störer beim PIVOT eliminieren
- Artikel 3: Pivot-Performance
- Artikel 4: Pivot-Performance mit Joins
Eliminierung von Störern
Wenn in der Tabelle weitere Spalten enthalten sind, dann kann das mit PIVOT zu unerwarteten Ergebnissen führen. Wenn die Tabelle OpenSchema bspw. auch noch die Spalte „Stoerer“ enthält:
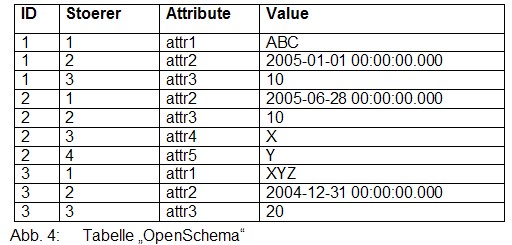
Wenn man nun einfach das PIVOT aus dem letzten Artikel einfach verwendet, dann führt das zu komischen Ergebnissen.
SELECT ID,
attr1 as Typ,
attr2 as Datum,
attr3 as Anzahl,
attr4 as Dings,
attr5 as Bums
FROM OpenSchema
PIVOT (
MAX("Value")
FOR Attribute IN ("attr1", "attr2", "attr3", "attr4", "attr5")
) AS pvt
ORDER BY ID
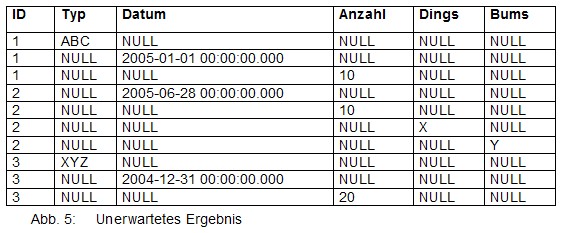
Das liegt an der impliziten Gruppierung aller Felder aus der Basistabelle. Es kann also passieren, dass durch eine unbedachte Tabellenerweiterung einige SELECTs ein völlig anderes Ergebnis liefern. Das ist nicht im Geiste von SQL, ist unangenehm und soll vermieden werden. Daher rate ich dazu PIVOT-Statements immer so zu formulieren, dass sie nicht auf der Basistabelle arbeiten, sondern einer Derived-Table:
SELECT ID,
attr1 as Typ,
attr2 as Datum,
attr3 as Anzahl,
attr4 as Dings,
attr5 as Bums
FROM (
SELECT ID, Attribute, Value
FROM OpenSchema) as dt
PIVOT (
MAX("Value")
FOR Attribute IN ("attr1", "attr2", "attr3", "attr4", "attr5")
) AS pvt
ORDER BY ID
Das liefert nicht nur in diesem Fall das erwartete Ergebnis, sondern auch nach weiteren Tabellenänderungen. Der Zugriffsplan ist entspricht dem ersten Artikel.



{kind=link}
{kind=link}