




Diese Vorführung einer Software vom M IT finde ich ziemlich beeindruckend. OK, nicht so futuristisch, wie das von neulich aber dennoch sehr sehenswert:
SQL Server 2005: Probekapitel aus dem Buch T-SQL Querying
 Quasi ergänzend zu den gestrigen Postings über Pivoting und den SQL-Hike habe ich auch noch einen Link auf ein kostenloses Probekapitel aus dem Buch "Microsoft SQL Server 2005 T-SQL Querying" von Itzik Ben-Gan, Lubor Kollar, Dejan Sarka und Kalen Delaney rausgesucht. In dem Kapitel Inside Chapter 06 – Aggregating and Pivoting Data geht es um Pivoting und CLR-Funktionen. Wenn meine Leseliste nicht schon so lang wäre, würde ich mir das Buch sofort besorgen… 🙁
Quasi ergänzend zu den gestrigen Postings über Pivoting und den SQL-Hike habe ich auch noch einen Link auf ein kostenloses Probekapitel aus dem Buch "Microsoft SQL Server 2005 T-SQL Querying" von Itzik Ben-Gan, Lubor Kollar, Dejan Sarka und Kalen Delaney rausgesucht. In dem Kapitel Inside Chapter 06 – Aggregating and Pivoting Data geht es um Pivoting und CLR-Funktionen. Wenn meine Leseliste nicht schon so lang wäre, würde ich mir das Buch sofort besorgen… 🙁
Vielleicht sollte ich es trotzdem tun und nur bei Bedarf nachschagen. 😉
SQL Server 2005: Pivoting & Unpivoting
Dem Feature "Pivoting/Unpivoting" stehe ich etwas zwispältig gegenüber: Einerseits habe ich in der Vergangenheit schon mehrfach die Anfrage von Entwicklern bekommen, wie man sowas macht (meist noch in den späten 90ern als wir von Btrieve auf Sybase SQL-Anywhere umstellten). Andererseits sind die zugrundeliegenden Ursachen in der Regel eine "schlechte" Datenmodelierung: Wert-Tabellen, wie sie ein index-sequentiellen Systemen üblich waren. Ich bevorzuge echte relationale Datenmodelle.
In den letzten Jahren habe ich aber auch erlebt, dass es mindestens eine Situation gibt, bei der man um solche Tabellen nicht rumkommt: Wenn man mit relationalen Mitteln eine Art OLAP-System nachbilden will, dann ist es sinnvoll alle möglichen "Fakten" in der gleichen Tabelle unterzubringen und deren Werte im gleichen Feld zu speichern. Damit kann man dann sehr einfach, sehr flexible Auswertungsmöglichkeiten schaffen. Mein Kollege Michael brauchte ziemlich lange, um mich davon zu überzeugen… 😉
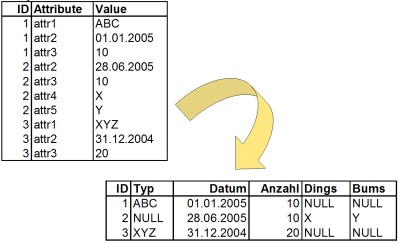
Die Werte aus einer Werte-Tabelle werden in eine echte Tabellen übertragen.
Dabei bekommen die einzelnen Attribute auch gleich sinnvolle Namen, z.B. wird "attr1" zu "Typ", "attr2" zu Datum" "attr3" zu "Anzahl" usw.
Der entsprechende PIVOT-Befehl geht so:
SELECT ObjectID, attr1 as Typ,
attr2 as Datum, attr3 as Anzahl,
attr4 as Dings, attr5 as Bums
FROM OpenSchema
PIVOT( Max("Value")
FOR Attribute IN ("attr1", "attr2", "attr3", "attr4", "attr5")
) AS pvt
ORDER BY ObjectID
Wenn man das Bedürfnis hat genau den umgekehrten Weg zu gehen: aus einer normalisierten Tabelle die Ergebnisse in Form einer Wert-Tabelle zu bekommen, dann geht das mit UNPIVOT:
SELECT ObjectID, Attribute, "Value"
FROM ( SELECT ObjectID, cast(Typ as sql_variant) as attr1, cast(Datum as sql_variant) as attr2, cast(Anzahl as sql_variant) as attr3, cast(Dings as sql_variant) as attr4, cast(Bums as sql_variant) as attr5
FROM FixSchema) as "Value"
UNPIVOT
(
"Value"
FOR Attribute IN ("attr1", "attr2", "attr3", "attr4", "attr5")
) AS pvt
ORDER BY ObjectID
Wer noch genug hat: Eine besonders gute Darstellung des Pivotierens liefert wieder mal Itzik Ben-Gan. Die Folien von seinem Vortrag "Advanced T-SQL Techniques" zur TechEd 2006 in Israel stehen bei microsoft.com (siehe "Advanced T-SQL Techniques"). Ich glaube, sie sind auch ohne seinen Text verständlich. Als ich ihn 2005 in London persönlich erleben durfte, zeigte er ganz ähnliche Folien. Deswegen bin ich da nicht repräsentativ.
Home-Computer von 1954
 Michael schickte mir beiliegendes Bild, dass ich sehr gelungen finde.
Michael schickte mir beiliegendes Bild, dass ich sehr gelungen finde.
Leider ist es eine Fälschung, wie man popularmechanics.com nachlesen kann. Wenn man genau hinschaut, dann erkennt man die Manipulationen sogar.