




Etwas das mir beim Microsoft SQL Server 2005 besonders gut gefällt, sind die Ranking-Functions: row_number, rank, dense_rank und ntile:
Hier ein Aufrufbespiel:
SELECT OrderID, Quantity,
row_number() OVER (ORDER BY quantity) AS "row_number()",
rank() OVER (ORDER BY quantity) AS "rank()",
dense_rank() OVER (ORDER BY quantity) AS "dense_rank()",
ntile(10) OVER (ORDER BY quantity) AS "ntile(10)"
FROM Northwind.dbo."Order Details"
WHERE ProductID=1
ORDER BY Quantity
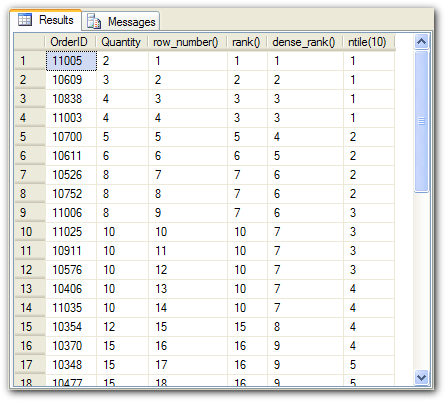
row_number liefert eine Nummerierung. Dabei muss man aber beachten, dass die Nummerierung nur dann eindeutig reproduzierbar ist, wenn die Sortierung präzise ist. Im obigen Beispiel kann es mehrere Order-Details mit der gleichen Anzahl geben. Deswegen ist die Row_Number hier "nicht deterministisch", sondrn könnte beim nächsten Aufruf anders Lauten. Die Abhilfe ist ganz einfach: Die Order-BY so erweitern, dass sie eindeutig ist.
ntile(n) verteilt die Datensätze gleichmäßig in n Töpfe. Die Töpfe werden dabei nummeriert. Die Reihenfolge basiert intern auf der Row_Numer. Deswegen ist es auch bei NTile von der genauen Sortierung abhängig, ob die Werte deterministisch sind oder nicht. Die Töpfe werden dabei immer reihum aufgefüllt, d.h. die vorderen Töpfe haben in der Regel ein Mitglieder mehr als die hinteren.
rank liefert den Rang, wie bei den olympischen Spielen: Wenn zwei den gleichen Werte haben, dann teilen sie sich den ersten Platz und der nächste sitzt auch Platz 3. Rank ist deswegen immer deterministisch.
dense_rank liefert den Rang, ohne Lücken. Auch diese Funktion ist immer deterministisch.
Wer sie noch nicht kennt, dem würde ich sie sehr ans Herz legen. Vertiefende Infos, insbesondere zu den Alternativen am Microsoft Sql Server 2000 werden in folgenden Beispielen von Itzik Ben-Gan besonders gut beschrieben (in den Beispielen nach "Rank" suchen, sie sind gut kommentiert).
Für die Vertiefung empfehle ich den Einsatz mit Partitions (in Gruppen durchzählen).